Recurrent Neural Networks Report
A short three-pager on Recurrent Neural Networks, touching on similarities and differences between GRU & LSTM approaches toward any future problem statement involving analyzing large-scale time series e.g. Price Prediction of a particular stock on the S&P 500.
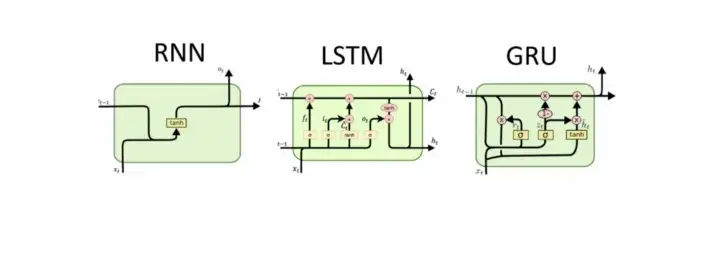
Long Short Term Memory vs Gated Recurrent Units.
Abstract
With the emergence of Recurrent Neural Networks (RNN) in the ’80s, followed by more sophisticated RNN structures, namely Long-Short Term Memory (LSTM) in 1997 and, more recently, Gated Recurrent Unit (GRU) in 2014, Deep Learning techniques enabled learning complex relations between sequential inputs and outputs with limited feature engineering.
In short, these RNN techniques hold great potential for analyzing large-scale time series in ways that were not previously practical.
In this report, I’d like to give you a bit of an introduction to some of the RNN structures, such as LSTM, and GRU, and help you get started building an understanding of the similarities and differences between these two approaches.
Background: Recurrent Neural Networks.
Recurrent neural networks are a class of neural networks used for sequence modeling. They can be expressed as time-layered networks in which the weights are shared between different layers.
Recurrent neural networks can be hard to train because they are prone to vanishing and exploding gradient problems.
Problem: Vanishing Gradient / Short-Term Memory.
Recurrent Neural Networks suffer from short-term memory. If a sequence is long enough, they’ll have a hard time carrying information from earlier time steps to later ones. So if you are trying to process a paragraph of text to make predictions, RNNs may leave out important information from the beginning.
In RNN to train the network, you backpropagate through time, at each step the gradient is calculated. During backpropagation, recurrent neural networks suffer from the vanishing gradient problem. Gradients are values used to update the weights of a neural network.
The vanishing gradient problem is when the gradient shrinks as it back propagates through time. If a gradient value becomes extremely small, it doesn’t contribute much learning. A smaller gradient means it will not affect the weight updating. Due to this, the network does not learn the effect of earlier inputs. Thus, causing short-term memory problem.
Solution: LSTMs & GRUs.
To overcome this problem two specialized versions of RNN were created. They are GRU(Gated Recurrent Unit) & LSTM(Long Short Term Memory). Suppose there are two sentences.
Sentence one is “My cat is …… she was ill.”, and the second one is “The cats ….. they were ill.” At the end of the sentence, if we need to predict the word “was” / “were” the network has to remember the starting word “cat”/”cats”.
So, LSTMs and GRUs make use of memory cells to store the activation value of previous words in long sequences.
They have internal mechanisms called gates that can regulate the flow of information. Gates are capable of learning which inputs in the sequence are important and storing their information in the memory unit.
By doing that, they can pass the information in long sequences and use them to make predictions. From the figure above we see that GRU has two gates; a reset gate & update gate while the LSTM has three gates; forget, input & output.

Comparisons between GRU and LSTM.
LSTMs and GRUs essentially function just like RNNs, but they’re capable of learning long-term dependencies using mechanisms called “gates.” These gates are different tensor operations that can learn what information to add or remove to the hidden state. Because of this ability, short-term memory is less of an issue for them.
The GRU is simpler and enjoys the advantage of greater ease of implementation(fewer tensor operations) and efficiency. It might generalize slightly better with less data because of a smaller parameter footprint, although the LSTM would be preferable with an increased amount of data.
LSTM directly controls the amount of information changed in the hidden state.
Conclusion.
Through this article, we have understood the basic difference between the RNN, LSTM, and GRU units.
From the working of both layers i.e., LSTM and GRU, GRU uses fewer training parameters and therefore uses less memory and executes faster than LSTM. In contrast, LSTM is more accurate on a larger dataset.
One can choose LSTM if you are dealing with large sequences and accuracy is concerned, GRU is used when you have less memory consumption and want faster results.
A more effective approach for dealing with the vanishing and exploding gradient problems is to arm the recurrent network with internal memory, which lends more stability to the states of the network. The use of long short-term memory (LSTM) has become an effective way of handling vanishing and exploding gradient problems.